前回の前編記事から引き続き、開発アルバイトの山本です!!
2024 2/23 ~ 2/25 の2泊3日で軽井沢合宿を行いました。そしてメインプログラムとして3人ずつの5チームに分かれて開発を行いました!!
テーマは「業務改善ツールを作りまくる」です!!
※案件の内容などを含む場合は一部省略して記載しております。ご了承ください。
下記5チームのうち、今回は前編で紹介しきれなかった「soy-beans」「Over bet」「d3」の成果物を公開したいと思います!
メンバーのあらゆるアクションを可視化!成果をビジュアライズ!仕事を楽しくする!
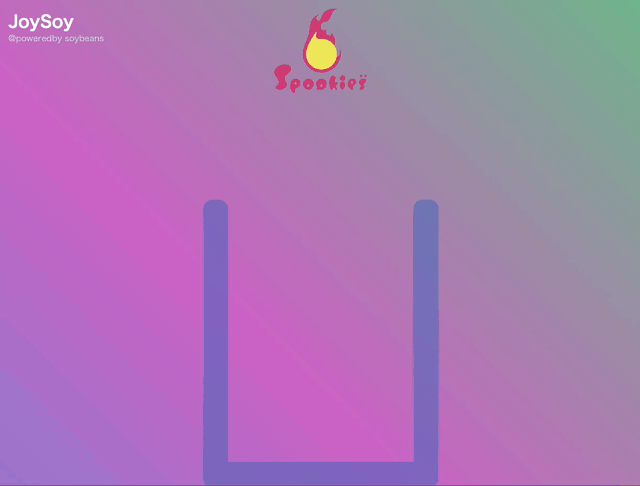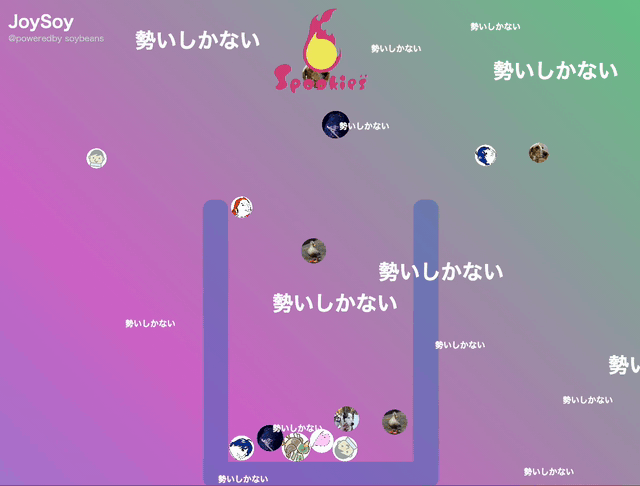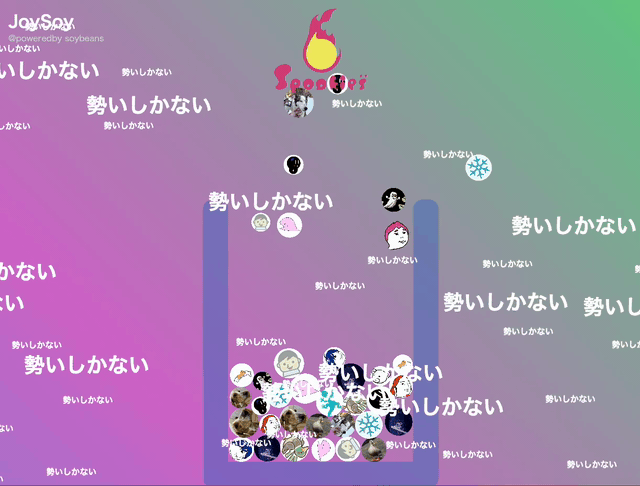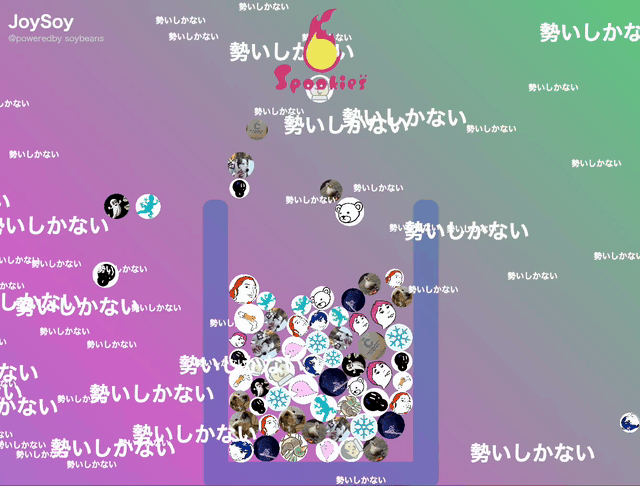
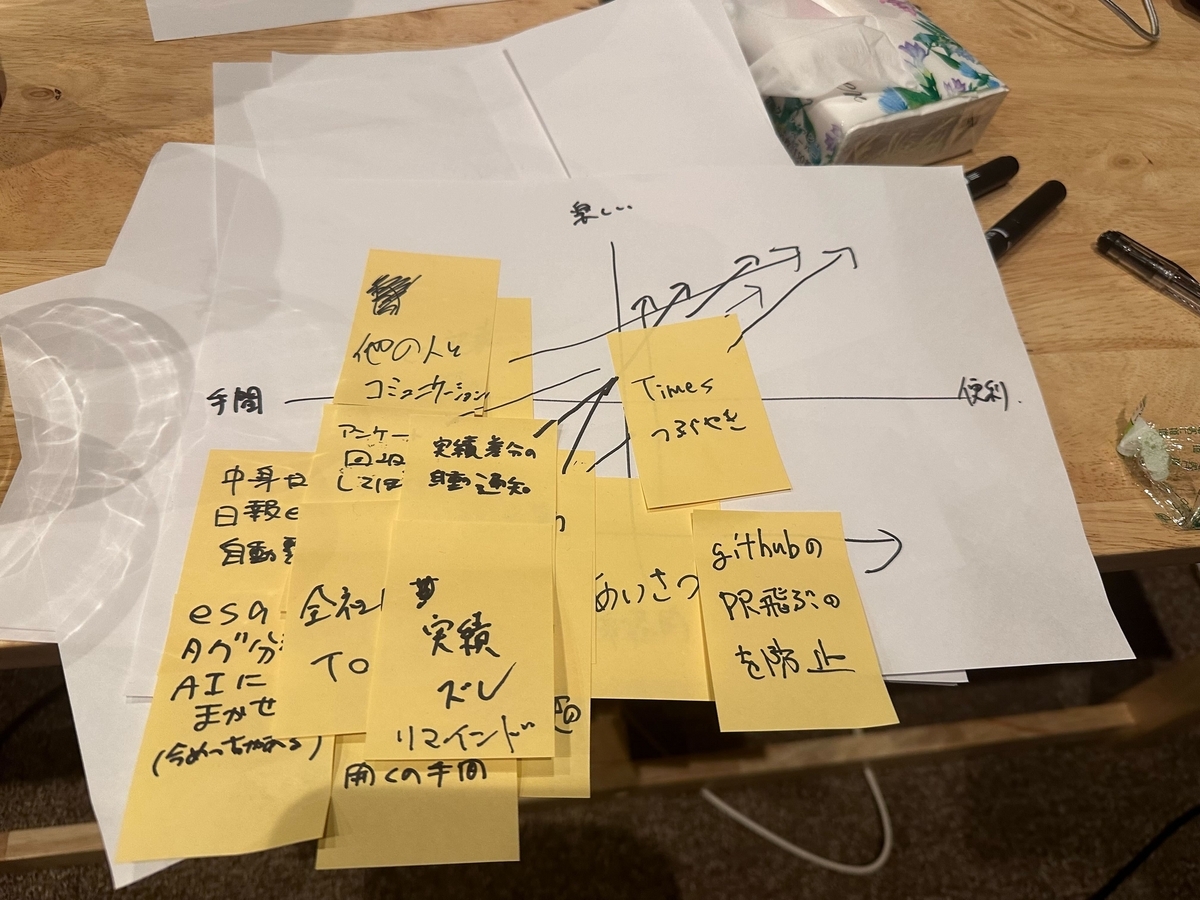
私たちは普段、案件ごとにチームが分かれて仕事をしています。チーム内ではみんなが今何をしているのか、どんな成果を上げていっているのか把握できていてもチーム間では少し見えにくい。また、チーム内でもいつどれくらいの仕事を成し遂げたのか、みんなが把握するのは難しい。
チームに関わらず、すべてのメンバーの成果、アクションを可視化したい、いい意味で競い合って高まりあいたい。
そんな気持ちからSpookiesメンバーの成果を確認できる!しかもなんだか楽しい!そんなツールを作りました。
技術構成
- バックエンド
- Pure PHP
- Slack API
- フロントエンド
- TS + Vite
- matter.js(物理演算)
- PixiJS(2Dグラフィック)
今回は合宿の期間中に動くところまで持っていくべく、メンバーのアクションとしてはSlackへの投稿を拾い上げるまでにスコープを絞りました。(今後アクションのバリエーションを増やしてできるだけたくさんのものを見える化したい。PRのマージなど!)
バックエンドはSlack投稿の巻き上げと、フロントエンド用のメンバーアクション取得APIを作成しています。
フロントエンドではそのAPIをポーリングしてビジュアライゼーションを行います。 最近流行った某ゲームから着想を得て、アクション=メンバーアイコンの球として画面上に溜まっていくところまで実現しました。ここは初めて使いましたがmatter.jsとPixiJSを導入し、ゲームライクな演出とともに見せています。
今回の合宿中では球が溜まっていくだけになっていますが、もっとゲーム的な仕組みを入れる&スコア化するなどしてより楽しいものにしていきたいですね。
タスクをこなすとポイントをもらえる制度があまりにも使いづらいので、改良しようのチーム!!
集計も表現も評価もなんもかんも足りてないけどまずは集計だけ!
(やりたいこと多すぎて話が発散しかけ、実装の動き出しが遅くなり後悔)

- 技術: Google Apps Script + clasp により git 管理しながらGASスクリプトの開発
- 技術: 生成AIを駆使して開発言語のスキル差を吸収
- python で実装して、GASへの変換
- マネジメント: 役割をしっかり分担して進めた
- 資料作成・発表・取りまとめ
- 技術検証・GAS環境の整備と調査
- pythonでメインプロトコル実装
ちなみに私(山本)はこのチームで開発させていただきました!このチームのメンバーは実は普段から一緒にいることが多いチームなので、default3を表すd3というチーム名になりました(笑) このチームは二つ開発しました!!
一つ目:作業チケット作成の簡略化
clickupを使って作業チケットを管理していますが、redmineの内容をもとに作っています。ただ、期日やタイトル、担当などを毎回入力して作成しなければなりません…。なのでこの作業を簡略化するためのツールを作りました!
chromeの拡張機能を使って、redmineとclickupのAPIキーを入力して、redmineの作業チケットが表示されているページに作成した「チケット作成ボタン」を押すと……なんとタイトルなどが綺麗に入力された状態のclickupのチケットが作成されます!!ちなみにchromeの拡張機能でのAPIキーの入力は一度行えば半永久的に保存されるので、一度APIキーを保存してしまえば、ボタンを押すだけでチケット作成ができてしまいます!!やったーー!!
ただ実は、担当や期日まで自動入力されたclickupのチケットは作成できませんでした。redmine上でのデータの型と、clickup上でのデータの型が違っていたことなどが原因で、時間内に実装することができませんでした…今後も是非機会を見つけて実装していきたいと思います!
技術構成
- バックエンド:NestJS
- フロントエンド(chrome拡張):TS + Vite
二つ目:作業チケットの検索です!
redmine上でチケットの検索を行うことはできますが、チケットのアサインが自分以外の人になってしまうと…悲しいことに検索することができません!!そこで、過去一度でもアサインされたチケットを検索できるようなWebアプリケーションを開発しました! フリーワード検索や、チケットIDでの検索、担当したことがあるチケットなどの項目で絞り込みを行うことができます!
技術構成
- Next.js v14.1.0
- App Router
- SSG ビルド
- linaria
- Router Handler
- Redmine REST API
見つかった課題
- 実は「現在担当している」による絞り込みは実装できていない(間に合わず...)
- SpoGPT による MR の自動生成も実装できなかった
- チケットの詳細から MR の内容と、検証すべきテスト内容の自動生成
- Redmine API の使いにくさ
- 例えば「〇〇というキーワードを含んでいる、過去に自分が対応したチケット」という検索は API のみでは実現できない
- 「過去に自分が対応した」で検索できる手段はない
- 本システムを通してチケットを作成・チケットデータを蓄積していくことで、このような検索にも対応できるようになる
- あくまでもタスク管理ツールであるので、複雑な検索には対応できない
- 「過去に自分が対応した」で検索できる手段はない
- 例えば「〇〇というキーワードを含んでいる、過去に自分が対応したチケット」という検索は API のみでは実現できない
終わりに
それぞれのチームが違う視点で業務改善を行うツールを開発しており、最後の成果発表会では大盛り上がりでした!ここで開発したものを今後も拡張していって、運用までしていけたら幸せだなと思いました!
3日間とても楽しかったです!ありがとうございました!